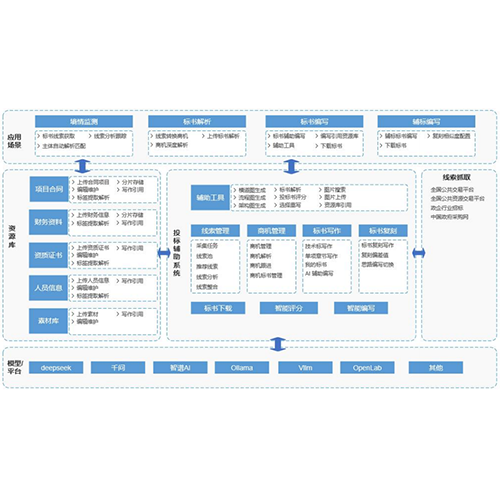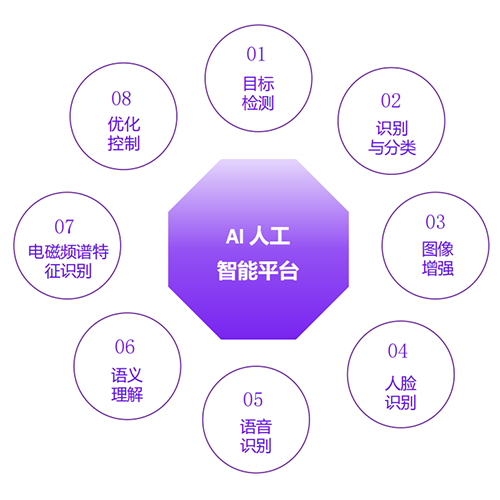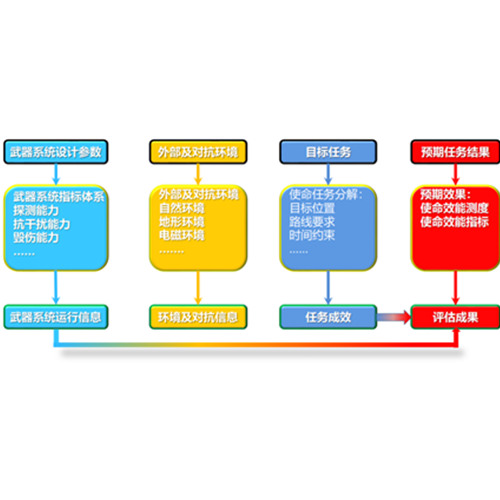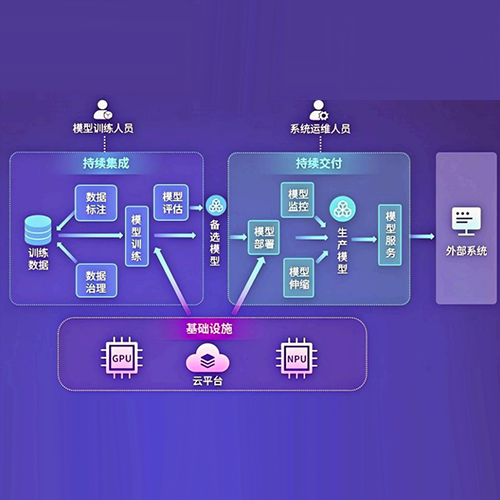
系统简介
大模型训练(及服务)平台集成了数据管理、模型管理、CI/CD流程编排、GPU/NPU资源调度、自动伸缩等能力和相关最佳实践,为大模型的训练和服务提供了全面支持。该平台通过自动化和智能化的管理手段,显著提升了模型训练的效率和质量,并降低了服务成本。
系统优势
支持自动化的资源调度和伸缩配置,可根据训练任务的需求动态调整资源,提高训练效率。
用户可根据需求调整训练数据集,自定义训练任务如选择模型架构调整超参数、设定训练轮数等还可回溯历史版本。
提供模型管理和服务管理功能,用户可以方便地查看和管理自己的模型和服务包括配置、授权、监控等。
API接口设计可高效调用已经训练好的模型实现快速模型部署。
支持服务的上下线管理和用户授权管理,确保服务的高可用性和安全性。
提供全面的服务监控功能,包括服务调用统计、服务监控总览等,帮助用户及时发现和解决问题。
核心功能
分布式训练引擎
支持模型并行与数据并行混合训练模式,自动优化计算资源分配,实现千亿参数级模型高效训练,大幅缩短训练周期。
自适应资源调度
智能GPU/TPU集群管理,动态调整计算资源,支持弹性扩展,优化资源利用率,降低大模型训练成本。
模型压缩与部署
集成模型量化、剪枝与蒸馏工具,支持多场景部署优化,在保持性能的同时降低推理成本,加速大模型落地应用。
超高训练效率
优化的分布式训练框架,支持万亿token级数据训练,比传统方案提升3-5倍效率。
弹性扩展能力
从百亿到千亿参数模型无缝扩展,支持动态增减计算节点,适应不同规模模型需求。
资源成本优化
智能资源调度与训练策略,降低30-50%计算资源消耗,大幅节约大30-50%计算资源消耗,大幅节约大模型训练成本。
企业级安全保障
全链路数据加密,模型访问控制,满足企业级数据安全与合规要求,保护核心AI资产。
 如果您对此感兴趣,欢迎问问展商吧!
暂无数据暂无数据如果您对此感兴趣,欢迎问问展商吧!
如果您对此感兴趣,欢迎问问展商吧!
暂无数据暂无数据如果您对此感兴趣,欢迎问问展商吧!



 CHN
CHN EN
EN